La arquitectura de datos es un elemento fundamental para que los sistemas de gestión de la información sirvan de manera adecuada a los diferentes estamentos de la empresa, en todos y cada uno de sus niveles. Está compuesto por la estrategia y políticas -que emanan desde la dirección- y los modelos y reglas - establecidos por los expertos en la materia - para definir de qué manera se extraen, manejan, clasifican, almacenan y explotan los datos, teniendo siempre en cuenta las limitaciones que aporta la infraestructura tecnológica de la que disponga la empresa.
En este sentido, la buena estrategia corporativa resulta fundamental, puesto que luego echar marcha atrás es caro y doloroso: es por ello que un buen diseño asesorado por expertos resulta de máximo interés. De esta manera, ni el diseño ni la calidad de la arquitectura de bases de datos se verán afectadas.
Por otro lado, malas arquitecturas puede provocar sobrecostes y un tortuoso proceso de reparación. Ejemplos comunes que pueden estar impactados por lo que comentamos, son, por ejemplo, los de migración de datos, o los cambios necesarios para dar cumplimiento a la RGPD (Reglamento General de Protección de Datos).
El origen de la arquitectura de datos
Todo nace y pivota en torno a una de la tecnologías relacionadas con la Industria 4.0, el big data: volúmenes masivos de datos, y además de todo tipo, imposibles de ser analizados con las herramientas informáticas convencionales, por lo que se precisa de las herramientas que esta aporta con el fin de ayudar de manera inteligente en la toma de decisiones.
Partiendo de esta base, la arquitectura nos debe ayudar a definir el origen y los tipos de datos necesarios para el buen desarrollo del negocio. ¿Y qué se busca? Pues un sistema que cumpla los siguientes requisitos:
- Sencillo como para que los interesados puedan comprenderlo
- Coherente
- Estable
- A un precio adecuado al tamaño de la empresa, a su propósito y lo que pueda pagar
Al final del día buscamos realizar despliegues robustos, rápidos y consistentes para cumplir con las necesidades de información de la empresa.
Diseño de la arquitectura de datos
Para diseñar un sistema eficiente, controlar el flujo de datos y garantizar su protección,
es importante conocer la relación y el tipo de gestión necesaria para cada tipo de dato desde el principio. En este sentido, un
DataBase Management Systems (DBMS en inglés / Sistemas de Gestión de Bases de Datos) es un software orientado al manejo de base de datos, cuya función es
servir de interfaz entre las BBDD, el usuario y otras aplicaciones. Las DBMS realizan funciones importantes que garantizan la integridad y consistencia de los datos en cualquier base de datos.
Las funciones más importantes del sistema de gestión de bases de datos vienen definidas por la Organización
DAMA International, y son:
1. Data Governance - Planificación, supervisión, y control en la gestión y uso de datos.
Data Governance o gobierno de datos versa sobre la gestión de la disponibilidad, integridad, usabilidad y seguridad de los datos utilizados en una organización. Un buen programa de Data Governance incluye:
- Un órgano o consejo de gobierno
- Un conjunto de procedimientos definidos
- Un plan para ejecutar dichos procedimientos.
El objetivo del Data Governance es la planificación, supervisión y control sobre la gestión y el uso de los datos. Incluye las personas, los procesos y las tecnologías necesarias para administrar y proteger los activos de datos de la empresa a fin de garantizar unos datos corporativos comprensibles, correctos, completos, confiables y seguros. Abarca todo el ciclo del análisis: desde la extracción de los datos hasta su visualización, incluyendo el almacenamiento y procesamiento.
La parte más importante de un Data Governance son los procesos ya que recoge las normas y regulaciones que permiten que haya una metodología común en toda la organización a la hora de tratar la información. Algunas tareas que se definen en este apartado son la documentación complementaria a los desarrollos (facilitando así las revisiones y auditorías) o los permisos que tienen los usuarios.
La aplicación de un Data Governance no solo incumbe al equipo de IT, también a los encargados de tomar decisiones sin importar su nivel o área en la organización. Es más, significa un cambio de mentalidad y organizativo, puesto que contribuye a la digitalización de la empresa y a agilizar la toma de decisiones en los distintos departamentos.
Los beneficios del Gobierno de datos son:
- Una mejor gestión de los datos y toma de decisiones
- Contar con un proceso estandarizado en el análisis de datos
- Proceso de toma de decisiones transparente y basado en datos
- Dotar a la organización de datos fiables y de calidad
- Reducir costes y optimizar los esfuerzos, ya sean económicos o humanos
- Proteger la seguridad y la privacidad de los datos.
Procesos del Data Governance
Los procesos de un Data Governance se dividen en tres grandes bloques:
1. Source Systems
Son las bases de datos que proporcionan la información que deseamos analizar. Aquí entraría todos los datos sin modificar (raw data) proveniente de los ERPs, CRMs y demás fuentes de información.
2. Data Warehouse
Es la parte más laboriosa del proceso y explicarla en profundidad daría para una entrada a parte. En pocas palabras, engloba todas las acciones de tratamiento de datos: desde la recogida de los Source Systems, pasado por la integración, almacenamiento, limpieza y por último la seguridad. Este apartado incluye los mecanismos que hay que llevar en los despliegues entre entornos y administración del proceso de carga. Dichos procesos deben ser monitorizados para saber si los datos han sido actualizados correctamente.
3. Reporting
Es el proceso final y en el se utilizan herramientas de Business Intelligence como Power BI, QlikView o Qlik Sense (entre otras) para generar aplicaciones de cuadros de mandos interactivos y accesibles desde cualquier dispositivo con acceso a internet. Además, se puede realizar análisis estadísticos y analíticos con objetos visuales gracias a la integración de R y Python.
2. Data architecture: establecimiento de modelos, políticas y reglas para gestionar los datos.
Arquitectura de datos son los modelos, políticas, reglas y estándares que nos indican de qué manera tenemos que almacenar, organizar e integrar los datos que recoge una compañía con el objetivo de que sean aprovechables y útiles. Ante ello, es necesario conocer de manera exhaustiva cómo diseñar una arquitectura de datos o al menos qué debería de tener para que esta fuera alineada con los objetivos comerciales de la empresa.
En la nueva era del Big Data y el Data Science, es de vital importancia para una empresa disponer de una arquitectura de datos:
- Centralizada
- Alineada con los procesos comerciales
- Que se adapta al crecimiento del negocio
- Que evoluciona con los avances tecnológicos.
Una arquitectura de datos exitosa proporciona:
- Claridad sobre cada aspecto de los datos, lo que permite a los científicos de datos trabajar con datos confiables de manera eficiente y resolver problemas comerciales complejos.
- Prepara a una organización para aprovechar rápidamente las nuevas oportunidades de negocios al servirse de las tecnologías emergentes
- Mejorar la eficiencia operativa al administrar la entrega compleja de datos e información en toda la empresa.
A pesar de lo que pueda parecer, la arquitectura de datos es una disciplina relativamente nueva. El papel de Data Architect ha recaído, tiempo atrás, en analistas de negocio senior, desarrolladores de ETL y científicos de datos. Hoy día, estos perfiles conviven con otro ya más especializado en la labor de Data Architecture.
Debido a este hecho, quizás la arquitectura de los datos de la mayoría de las empresas hoy día, no sean las más adecuadas. De este modo, nos solemos encontrar con los siguientes errores frecuentes:
- Las empresas que manejan por sí mismas los datos suelen tener varios departamentos de IT, que trabajan en silos con sus propios estándares y arquitectura de datos.
- Las aplicaciones y los procesos se crean en función de los requisitos empresariales individuales, sin estándares de arquitectura de datos a seguir.
- El arquitecto de datos tiene la función de centrarse únicamente en un número limitado de áreas técnicas y posee un conocimiento comercial limitado sobre los datos.
- Los proyectos de IT se administran sin considerar la arquitectura de datos como parte de la fase de diseño, de este modo, los científicos e ingenieros de datos codifican su camino sin un proceso de gestión de datos coherente.
Debido a esto, no es difícil encontrar sistemas de datos desarticulados, brechas entre equipos y silos de información entre departamentos.
Estas situaciones conllevan:
- Un bajo rendimiento de los sistemas con muchas transferencias
- Mucho tiempo para solucionar problemas cuando surge un problema de datos de producción
- Una falta de responsabilidad para llegar a la solución correcta en todos los sistemas
- Una falta de capacidad para evaluar el impacto de un cambio.
- Un enorme esfuerzo a la hora de analizar e investigar en el momento de realizar una migración o rediseño a una plataforma tecnológicamente superior.
Pasos para poner en marcha una correcta arquitectura de datos
Una empresa que quiera sacar provecho de sus datos y que además está alineada con los objetivos comerciales debe, sí o sí, tener muy bien diseñada la arquitectura de estos. Para ello, debe de seguir un proceso de análisis y estructuración, que le ayude a conseguir ese objetivo. Se recomienda seguir los siguientes pasos:
1. Diseñar la arquitectura de datos al nivel conceptual, basándolo en procesos y operaciones comerciales.
En cualquier departamento de IT moderno, los procesos comerciales deberían de ser compatibles e impulsados por entidades de datos, flujos de datos y reglas comerciales aplicadas a los datos. Un arquitecto de datos, por lo tanto, necesita tener un profundo conocimiento del negocio, así como del sector.
Cumpliendo con esas bases, se puede comenzar a construir un plan de datos adecuado para el negocio. Es el momento de diseñar cada entidad de datos, así como cada flujo de datos que habría por debajo de cada proceso comercial.
Este es el momento para planificar las siguientes áreas:
- Las entidades de datos centrales y los elementos de datos, como los de clientes, productos y ventas.
- Los datos de salida que se necesitan.
- Los datos de origen que se recopilarán y transformarán, o harán referencia para producir los datos de salida.
- Cuál es la propiedad de cada entidad de datos y cómo se debe consumir y distribuir según los casos de uso de la empresa.
- Políticas de seguridad que se aplicarán a cada entidad de datos.
- Las relaciones entre las entidades de datos, como integridad de referencia, reglas de negocio o secuencia de ejecución.
- Clasificación estándar de datos y taxonomía.
- Estándares de calidad de datos, operaciones y acuerdos de nivel de servicio (SLA).
Este nivel conceptual de diseño consiste en las entidades de datos subyacentes que soportan cada función comercial. El plan es crucial para el diseño exitoso y la implementación de arquitecturas empresariales y de sistemas y sus futuras expansiones o actualizaciones.
2. Diseñar la arquitectura de datos de nivel lógico
A esta fase se le llama en ocasiones, modelado de datos al considerar qué tipo de base de datos o formato de datos usar. Esta fase lo que hace, es conectar los requisitos comerciales a las plataformas y sistemas tecnológicos.
Sin embargo, la mayoría de las organizaciones tienen un modelado de datos diseñado solo dentro de una base de datos o sistema particular, dada la función aislada del modelador de datos.
Lo que se debe de hacer, por tanto, para desarrollar una arquitectura de datos exitosa, es dar con un enfoque integrado, considerando los estándares aplicables a cada base de datos o sistema, y los flujos de datos entre estos sistemas de datos.
Para ello, las siguientes 5 áreas deben diseñarse de manera sinérgica:
- Las convenciones de nomenclatura para entidades y elementos de datos deben aplicarse de manera coherente a cada base de datos. Además, la integridad entre la fuente de datos y sus referencias debe hacerse cumplir si los mismos datos tienen que residir en múltiples bases de datos.
- Las políticas de archivo y retención de datos a menudo no se consideran o establecen hasta cada etapa tardía de la producción, lo que causa el desperdicio de recursos, estados de datos inconsistentes en diferentes bases de datos y un bajo rendimiento de las consultas y actualizaciones de datos.
- Si bien el diseño conceptual ha definido qué componente de datos es información confidencial, el diseño lógico debe tener la información confidencial protegida en una base de datos con acceso limitado, replicación de datos restringida, tipo de datos particular y flujos de datos seguros para proteger la información.
- Las réplicas de datos excesivas pueden generar confusión, mala calidad de datos y bajo rendimiento. Cualquier réplica de datos debe ser examinada por el arquitecto de datos y aplicada con principios y disciplinas.
- La forma en que los datos fluyen entre diferentes sistemas de bases de datos y aplicaciones debe definirse claramente en este nivel.
3. La gobernanza de datos como clave para el éxito continuo de la arquitectura de datos
La arquitectura de datos no es estática, sino que debe gestionarse, mejorarse y auditarse continuamente, estando siempre en continua adaptación. La gobernanza de datos, como hemos visto anteriormente, es fundamental en este caso, ya que garantiza que la arquitectura de datos empresariales se diseñe e implemente correctamente a medida que se inicia cada nuevo proyecto.
3. Data modeling & design: diseño de la base de datos, y gestión de la implementación y del soporte técnico.
El modelo y diseño de datos no es sino el conjunto de especificaciones que se emplean para estructurar y organizar los datos relacionales. En la función de Data Modeling & Design se desciende a un nivel inferior en la estructura sobre la que se organizan los datos, alcanzándose el nivel de base de datos. A diferencia de la función de arquitectura de datos, que es global y describe cómo se estructura el dato y cómo es comprendido por la empresa; en esta función, modelar y diseñar, ya se está entrando en detalle en el dato en sí, siendo por tanto mucho más específica.
La función se despliega en dos procesos que se han de desarrollar conjuntamente y que son:
- Modelar: es la tarea de estructurar y organizar los datos. El modelo de datos es un diagrama que usa texto y símbolos, y que se utiliza para representar no sólo los datos, sino también sus relaciones. Se corresponde con el diseño lógico.
- Diseñar: es convertir el modelo de datos lógico en el diseño físico, hacerlo realidad, transformarlo en algo tangible.
El objetivo que se persigue con esta función es poder utilizar los datos como recurso.
4. Data Storage Management - Gestión del almacenamiento de datos: esto es, definición del lugar de almacenamiento, y la cantidad y el tipo de datos por almacenar
La función de Data Storage se ocupa del conjunto de especificaciones que sirven para definir cómo, cuándo y qué se almacena.
En toda organización, independientemente del sector o el tamaño, puede observarse que los datos crecen a un ritmo exponencial y eso genera un problema a la hora de almacenarlos. Ya no es suficiente con almacenar, sino que hay que definir una estrategia que siente las bases del almacenamiento.
La función de Data Storage busca implementar buenas prácticas y políticas que cumplan con los objetivos fijados desde el Data Governance, de forma que no se pierda alineación. Un ejemplo gráfico sería comparar la gestión de los alimentos a guardar en la despensa de una casa con la de los alimentos a guardar en un supermercado. Mientras que en el primer caso el volumen es tan manejable que no requiere de un orden, en el segundo, el orden lógico es indispensable.
¿Qué implica la gestión de la información almacenada?
La recopilación de datos y el análisis manual son procesos que llevan mucho tiempo, y, por eso, transformar los datos en información es laborioso y costoso si no se cuenta con el respaldo de herramientas automatizadas.
El tamaño y el alcance del mercado de análisis de información se está expandiendo a un ritmo cada vez mayor, desde automóviles autónomos hasta análisis de cámaras de seguridad y desarrollos médicos. En cada industria, en cada parte de nuestras vidas, hay un cambio rápido y la velocidad a la que se producen las transformaciones está aumentando.
Se trata de una constante evolución que se basa en datos. Esa información procede de todos los datos nuevos y antiguos recopilados, cuando se emplean para desarrollar nuevos tipos de conocimiento.
La relevancia que ha adquirido la gestión de la información hace que surjan muchas preguntas sobre los requisitos aplicables a todos los datos recopilados y la información desarrollada.
Data storage se sitúa en el punto de mira, especialmente por cuestiones relativas al cumplimiento regulatorio y a la seguridad:
- Actualmente, las empresas se encuentran con la necesidad de hacer frente a desafíos de corporate compliance. El motivo es que existen muchos requisitos basados en el tipo de información y datos que se almacenen. Comprender lo que se requiere desde el punto de vista de la gobernanza para sus datos o la información resultante es posible aplicando las mejores prácticas para cada industria y observando las exigencias que imponen leyes, normas y reglamentos, como el GDPR en Europa.
- En referencia a la protección de la información, hay organizaciones que optan por recurrir al cifrado de datos en reposo, que encripta el dispositivo de almacenamiento para que, si se elimina del sistema, sea prácticamente imposible acceder a los datos (el grado de dificultad depende del algoritmo de cifrado y el tamaño, complejidad y entropía de la clave o claves para el dispositivo). También se aseguran de permanecer actualizados, para garantizar la protección que sus activos informacionales requieren y evitar que la sofisticación de la amenaza pueda vulnerarla.
Además de tomar en consideración este tipo de cuestiones al gestionar el data storage, las organizaciones tendrán que tomar decisiones acertadas en temas de arquitectura de datos y de plazos de conservación de la información almacenada. Se trata de detalles importantes si se quiere cumplir con los objetivos del negocio en las áreas de rendimiento, disponibilidad e integridad de los datos.
Beneficios de un data storage adecuado para la organización
Existen muchas ventajas asociadas a llegar una buena gestión de la información almacenada. De entre los beneficios que reporta el cubrir adecuadamente los requerimientos de la función de Data Storage y la gestión de datos serían, destacan los dos siguientes:
- Ahorro: la capacidad de un servidor para almacenar datos es limitada, por lo que guardar los datos sin una estructura, sin un orden lógico y careciendo de unos principios rectores, supone un encarecimiento que podría evitarse. Por el contrario, cuando data storage responde a un plan y las decisiones que se toman se alinean con la estrategia del negocio, se consiguen ventajas que se hacen extensibles a todas las funciones de la organización.
- Aumento de la productividad: cuando los datos no se han almacenado correctamente el sistema funciona de forma más lenta. Una de las estrategias que se suelen utilizar para evitar esto consiste en dividir los datos en activos e inactivos. Estos últimos se guardarían comprimidos y en un lugar diferente, para que el sistema siga siendo ágil, pero sin que ello suponga que quedan totalmente inactivos, ya que alguna vez puede ser necesario acceder a ellos de nuevo. Hoy día, con los servicios en la nube resulta mucho más sencillo encontrar el enfoque de data storage más apropiado para cada tipo de información.
Hay que evitar que sea cada aplicación la que decida cómo guardar los datos, y para ello la política de gestión de la información debería ser uniforme para todas las aplicaciones y dar respuesta a las siguientes cuestiones en cada caso:
- Cómo se almacena el dato.
- Cuándo se guarda el dato.
- Qué parte del dato o de la información se recoge.
En definitiva, a través del Data Storage se establecerá un responsable que viene determinado por el Data Governance, que es a su vez quién se encarga de definir los estándares y la forma de guardar la información, ya que no todos los silos pueden ser empleados.
Y esta es la manera de respaldar el objetivo común desde esta función y a través de los procedimientos, la planificación y la organización y del control que se ejerce de manera transversal y buscando siempre potenciar el lado pragmático del dato.
5. Data security - Gestión de la Seguridad: protección de la privacidad y la confidencialidad
En líneas generales, seguridad de datos se refiere a medidas de protección de la privacidad digital que se aplican para evitar el acceso no autorizado a los datos, los cuales pueden encontrarse en ordenadores, bases de datos, sitios web, etc. La seguridad de datos también protege los datos de una posible corrupción.
1. ¿Qué es seguridad de datos?
La seguridad de datos, también conocida como seguridad de la información o seguridad informática, es un aspecto esencial de TI en organizaciones de cualquier tamaño y tipo. Se trata de un aspecto que tiene que ver con la protección de datos contra accesos no autorizados y para protegerlos de una posible corrupción durante todo su ciclo de vida.
Seguridad de datos incluye conceptos como:
- encriptación de datos
- tokenización
- prácticas de gestión de claves
... todo ello en aras a ayudar a proteger los datos en todas las aplicaciones y plataformas de una organización.
Hoy en día, organizaciones de todo el mundo invierten fuertemente en la tecnología de información relacionada con la ciberdefensa con el fin de proteger sus activos críticos: su marca, capital intelectual y la información de sus clientes.
En todos los temas de seguridad de datos existen elementos comunes que todas las organizaciones deben tener en cuenta a la hora de aplicar sus medidas: las personas, los procesos y la tecnología.
2. Algunos conceptos que debes conocer
La seguridad de datos es un tema de suma importancia que nos afecta a casi todos nosotros. Cada vez son más los productos tecnológicos que de una u otra forma deben ser tenidos en cuenta para temas de seguridad y que se están introduciendo en nuestra vida cotidiana, desde smartwatches hasta vehículos sin conductor. Ya ha llegado la era del Internet de las Cosas (IoT) y, por supuesto, de los hacks relacionados con IoT. Todos estos dispositivos conectados crean nuevas “conversaciones” entre dispositivos, interfaces, infraestructuras privadas y la nube, lo que a su vez crea más oportunidades para que los hackers puedan escuchar. Todo esto ha impulsado una demanda de soluciones y expertos en seguridad de datos que sean capaces de construir redes más fuertes y menos vulnerables.
Tendencias recientes han demostrado que los ataques de ransomware están aumentando en frecuencia y en gravedad. Se ha convertido en un negocio en auge para ladrones cibernéticos y hackers, que acceden a la red y secuestran datos y sistemas. En los últimos meses, grandes empresas y otras organizaciones, así como también usuarios particulares, han caído víctimas de este tipo de ataques y han tenido que pagar el rescate o correr el riesgo de perder datos importantes.
Entonces, ¿qué conceptos deberíamos conocer que puedan ayudarnos a proteger nuestra red y prevenir esta nueva ola de ataques cibernéticos modernos?
Ingeniería de la seguridad de datos
Pensar en seguridad de datos y construir defensas desde el primer momento es de vital importancia. Los ingenieros de seguridad tienen como objetivo proteger la red de las amenazas desde su inicio hasta que son confiables y seguras. Los ingenieros de seguridad diseñan sistemas que protegen las cosas correctas de la manera correcta. Si el objetivo de un ingeniero de software es asegurar que las cosas sucedan, el objetivo del ingeniero de seguridad es asegurar que las cosas (malas) no sucedan diseñando, implementando y probando sistemas completos y seguros.
La ingeniería de seguridad cubre mucho terreno e incluye muchas medidas, desde pruebas de seguridad y revisiones de código regulares hasta la creación de arquitecturas de seguridad y modelos de amenazas para mantener una red bloqueada y segura desde un punto de vista holístico.
Encriptación
Si la ingeniería de seguridad de datos protege la red y otros activos físicos como servidores, computadoras y bases de datos, la encriptación protege los datos y archivos reales almacenados en ellos o que viajan entre ellos a través de Internet. Las estrategias de encriptación son cruciales para cualquier empresa que utilice la nube y son una excelente manera de proteger los discos duros, los datos y los archivos que se encuentran en tránsito a través de correo electrónico, en navegadores o en camino hacia la nube.
En el caso de que los datos sean interceptados, la encriptación dificulta que los hackers hagan algo con ellos. Esto se debe a que los datos encriptados son ilegibles para usuarios no autorizados sin la clave de encriptación. La encriptación no se debe dejar para el final, y debe ser cuidadosamente integrada en la red y el flujo de trabajo existente para que sea más exitosa.
Detección de intrusión y respuesta ante una brecha de seguridad
Si en la red ocurren acciones de aspecto sospechoso, como alguien o algo que intenta entrar, la detección de intrusos se activará. Los sistemas de detección de intrusos de red (NIDS) supervisan de forma continua y pasiva el tráfico de la red en busca de un comportamiento que parezca ilícito o anómalo y lo marcan para su revisión. Los NIDS no sólo bloquean ese tráfico, sino que también recopilan información sobre él y alertan a los administradores de red.
Pero a pesar de todo esto, las brechas de seguridad siguen ocurriendo. Es por eso que es importante tener un plan de respuesta a una violación de datos. Hay que estar preparado para entrar en acción con un sistema eficaz. Ese sistema se puede actualizar con la frecuencia que se necesite, por ejemplo si hay cambios en los componentes de la red o surgen nuevas amenazas que deban abordarse. Un sistema sólido contra una violación garantizará que tienes los recursos preparados y que es fácil seguir un conjunto de instrucciones para sellar la violación y todo lo que conlleva, ya sea que necesites recibir asistencia legal, tener pólizas de seguro, planes de recuperación de datos o notificar a cualquier socio de la cuestión.
Firewall
¿Cómo mantener a visitantes no deseados y software malicioso fuera de la red? Cuando estás conectado a Internet, una buena manera de asegurarse de que sólo las personas y archivos adecuados están recibiendo nuestros datos es mediante firewalls: software o hardware diseñado con un conjunto de reglas para bloquear el acceso a la red de usuarios no autorizados. Son excelentes líneas de defensa para evitar la interceptación de datos y bloquear el malware que intenta entrar en la red, y también evitan que la información importante salga, como contraseñas o datos confidenciales.
Análisis de vulnerabilidades
Los hackers suelen analizar las redes de forma activa o pasiva en busca de agujeros y vulnerabilidades. Los analistas de seguridad de datos y los profesionales de la evaluación de vulnerabilidades son elementos clave en la identificación de posibles agujeros y en cerrarlos. El software de análisis de seguridad se utiliza para aprovechar cualquier vulnerabilidad de un ordenador, red o infraestructura de comunicaciones, priorizando y abordando cada uno de ellos con planes de seguridad de datos que protegen, detectan y reaccionan.
Pruebas de intrusión
El análisis de vulnerabilidad (que identifica amenazas potenciales) también puede incluir deliberadamente investigar una red o un sistema para detectar fallos o hacer pruebas de intrusión. Es una excelente manera de identificar las vulnerabilidades antes de tiempo y diseñar un plan para solucionarlas. Si hay fallos en los sistemas operativos, problemas con incumplimientos, el código de ciertas aplicaciones u otros problemas similares, un administrador de red experto en pruebas de intrusión puede ayudarte a localizar estos problemas y aplicar parches para que tengas menos probabilidades de tener un ataque.
Las pruebas de intrusión implican la ejecución de procesos manuales o automatizados que interrumpen los servidores, las aplicaciones, las redes e incluso los dispositivos de los usuarios finales para ver si la intrusión es posible y dónde se produjo esa ruptura. A partir de esto, pueden generar un informe para los auditores como prueba de cumplimiento.
Una prueba de intrusión completa puede ahorrarte tiempo y dinero al prevenir ataques costosos en áreas débiles que no conoces. El tiempo de inactividad del sistema puede ser otro efecto secundario molesto de ataques maliciosos, por lo que hacer pruebas de intrusión con regularidad es una excelente manera de evitar problemas antes de que surjan.
Información de seguridad y gestión de eventos
Hay una línea aún más holística de defensa que se puede emplear para mantener los ojos en cada punto de contacto. Es lo que se conoce como Información de Seguridad y Gestión de Eventos (SIEM). SIEM es un enfoque integral que monitoriza y reúne cualquier detalle sobre la actividad relacionada con la seguridad de TI que pueda ocurrir en cualquier lugar de la red, ya sea en servidores, dispositivos de usuario o software de seguridad como NIDS y firewalls. Los sistemas SIEM luego compilan y hacen que esa información esté centralizada y disponible para que se pueda administrar y analizar los registros en tiempo real, e identificar de esta forma los patrones que destacan.
Estos sistemas pueden ser bastante complejos de configurar y mantener, por lo que es importante contratar a un experto administrador SIEM.
Ciberseguridad: HTTPS, SSL y TLS
Internet en sí mismo se considera una red insegura, lo cual es algo que puede asustar cuando nos damos cuenta que actualmente es la espina dorsal de muchas de las transacciones de información entre organizaciones. Para protegernos de que, sin darnos cuenta, compartamos nuestra información privada en todo Internet, existen diferentes estándares y protocolos de cómo se envía la información a través de esta red. Las conexiones cifradas y las páginas seguras con protocolos HTTPS pueden ocultar y proteger los datos enviados y recibidos en los navegadores. Para crear canales de comunicación seguros, los profesionales de seguridad de Internet pueden implementar protocolos TCP/IP (con medidas de criptografía entretejidas) y métodos de encriptación como Secure Sockets Layer (SSL) o TLS (Transport Layer Security).
El software anti-malware y anti-spyware también es importante. Está diseñado para supervisar el tráfico de Internet entrante o el malware como spyware, adware o virus troyanos.
Detección de amenazas en punto final
Se pueden prevenir ataques de ransomware siguiendo buenas prácticas de seguridad, como tener software antivirus, el último sistema operativo y copias de seguridad de datos en la nube y en un dispositivo local. Sin embargo, esto es diferente para organizaciones que tienen múltiple personal, sistemas e instalaciones que son susceptibles a ataques.
Los usuarios reales, junto con los dispositivos que usan para acceder a la red (por ejemplo, teléfonos móviles, ordenadores portátiles o sistemas TPV móviles), suelen ser el eslabón más débil de la cadena de seguridad. Se deben implementar varios niveles de protección, como tecnología de autorización que otorga acceso a un dispositivo a la red.
Prevención de pérdida de datos (DLP)
Dentro de la seguridad de punto final hay otra estrategia de seguridad de datos importante: la prevención de pérdida de datos (DLP). Esencialmente, esto abarca las medidas que se toman para asegurar que no se envían datos confidenciales desde la red, ya sea a propósito, o por accidente. Puede implementarse software DLP para supervisar la red y asegurarse de que los usuarios finales autorizados no estén copiando o compartiendo información privada o datos que no deberían.
3. Seguridad de datos in house vs en la nube
A pesar del aumento en la adopción de la nube, muchas compañías siguen dudando en seguir adelante con esa transición debido a preocupaciones acerca de su seguridad. Estas preocupaciones van desde la privacidad de los datos hasta la pérdida de datos y brechas. Por estas razones hay algunas organizaciones que siguen dudando en transferir el control de sus datos a los proveedores de la nube. En realidad estas preocupaciones son exageradas. Veamos por qué:
Mejores capacidades de defensa
Para que los proveedores de la nube tengan éxito, deben administrar grandes volúmenes de datos. Esta capacidad requiere el empleo y la formación de grandes equipos específicamente capacitados para administrar, asegurar y operar una gigantesca infraestructura de nube y los datos alojados en su interior. La cantidad de experiencia necesaria para administrar una nube eclipsa la experiencia que la mayoría de las empresas individuales pueden tener. La experiencia que se encuentra en los proveedores de servicios gestionados por la nube está muy centrada en la seguridad de datos. Como resultado, los contratiempos debido a la falta de experiencia en seguridad en la nube están fuera de toda cuestión y la infraestructura de la nube está adecuadamente protegida contra vulnerabilidades.
Ciclos de vida de desarrollo seguro
La mayoría de soluciones locales se desarrollan a lo largo de años, a veces hasta décadas. Cuando surgen inquietudes y nuevos requisitos, los arquitectos y los gestores de soluciones se ven obligados a mejorar y actualizar sus sistemas. Este ciclo de desarrollo es similar para soluciones en la nube con una diferencia importante: la seguridad se desarrolla en la solución desde el principio. Especialmente en sistemas heredados más antiguos, algunas de las preocupaciones de seguridad de datos de hoy en día no fueron consideradas en sus etapas iniciales de despliegue.
Todo en una infraestructura de nube, desde las soluciones de software hasta los sistemas de monitorización y los procesos de administración de la infraestructura, están diseñados pensando en la seguridad de datos. Para muchos sistemas in situ, la seguridad puede haber sido una idea de última hora.
Auditoría continua
Si un proveedor de la nube es serio acerca de la seguridad de datos, esa seriedad se extiende a la auditoría continua, monitorización y pruebas de seguridad de todos los aspectos operacionales de la infraestructura. Además de garantizar una mayor fiabilidad de las soluciones, la auditoría continua garantiza que todo el software se actualiza a la última versión, se identifican y resuelven todas las anomalías en el rendimiento del sistema y se cumplen todos los requisitos de cumplimiento de seguridad. La monitorización constante asegura que cualquier comportamiento irregular sea inmediatamente identificado e investigado.
Automatización y Repetibilidad
La infraestructura de la nube se desarrolla pensando en automatización: menos intervención manual en funciones de rutina y menos oportunidades para que se cometan errores. Los servicios en la nube realizan un número limitado de tareas por diseño. La mayoría de las tareas abren una instancia virtual y cierran esa instancia. Estas tareas están estandarizadas, al igual que la mayoría del hardware, equipos de red, aplicaciones y sistemas operativos utilizados para realizar esas tareas. Esta estandarización facilita la seguridad de las infraestructuras cloud.
Debido a las mayores economías de escala involucradas, los principios de automatización y repetibilidad son esenciales en la implementación de nuevos sistemas.
Controles de acceso más estrictos
Una preocupación importante es la pérdida de control de datos para las empresas si los datos se encuentra fuera de su firewall. Este control se extiende a la creencia de que algunos empleados del proveedor de la nube tienen acceso general a sus datos confidenciales. Un proveedor de cloud gestionado adecuadamente tendrá varios roles compartiendo responsabilidades para toda la solución cloud sin que ninguna persona tenga acceso total a todos los componentes de la solución. En otras palabras, ninguna persona tiene el nivel de acceso necesario para amenazar la seguridad o confidencialidad de los datos de un cliente.
En las instalaciones vs en la nube
La idea de que las infraestructuras locales son más seguras que las infraestructuras en la nube es un mito. El acceso físico no autorizado a los centros de datos en la nube es extremadamente raro. Las peores infracciones ocurren detrás de los firewalls de las empresas y de sus propios empleados. Los datos en una nube pueden residir en cualquier número de servidores en cualquier número de ubicaciones, en lugar de un servidor dedicado dentro de la red local.
El acceso físico a los sistemas ya no es una preocupación válida. Las economías de escala requeridas por los proveedores de la nube han mostrado un menor número de interrupciones del servicio y recuperaciones más rápidas, reduciendo el tiempo de inactividad sufrido por los clientes de la nube. Los niveles más altos de automatización, normalización y auditoría garantizan que las firmas de virus y los parches de seguridad se actualizan rápidamente en toda la red: a menudo mucho más rápido que de lo que el personal de TI local puede realizar. La monitorización y la dotación de personal 24/7/365 permite identificar y resolver problemas rápidamente.
4. Productos y/o habilidades de seguridad de datos importantes para tu empresa
Las mejores soluciones de seguridad ayudan a las organizaciones a reducir el riesgo de seguridad de datos, respaldan las auditorías para el cumplimiento con regulaciones y privacidad, frenan el abuso de información privilegiada y protege los datos confidenciales y confidenciales.
A pesar de la inversión de miles de millones de dólares en seguridad de la información y gobierno de datos, muchas organizaciones todavía luchan por comprender y proteger sus activos más valiosos: datos confidenciales y sensibles.
La mayoría tienen poca confianza en cuanto a su ubicación, riesgo y crecimiento. Además, no entienden quién está accediendo a los datos, cómo están protegidos y si hay un uso sospechoso de ellos.
Comprender el riesgo de los datos sensibles es clave. El análisis de riesgo de datos incluye descubrir, identificar y clasificarlo, por lo que los administradores de datos pueden tomar medidas tácticas y estratégicas para asegurar que los datos sean seguros.Riesgo de cumplimiento
Las implicaciones y los costes de las brechas de seguridad de datos son noticia de primera plana y abarcan todo, desde la pérdida de puestos de trabajo hasta la pérdida de ingresos e imagen. A medida que el volumen y la proliferación de datos continúan creciendo, los enfoques de seguridad tradicionales ya no ofrecen la seguridad de datos necesaria.
Cuando el Reglamento General de Protección de Datos (GDPR) de la Unión Europea (UE) se convierta en ley el 25 de mayo de 2018, las organizaciones pueden enfrentarse a penalizaciones significativas de hasta el 4% de sus ingresos anuales. GDPR forzará a las organizaciones a entender sus riesgos de privacidad de datos y tomar las medidas apropiadas para reducir el riesgo de divulgación no autorizada de la información privada de los consumidores.
Algunas investigaciones citan las condiciones que seguirán desafiando a las organizaciones a salvaguardar sus datos y también aumentarán su responsabilidad para proteger su información:
- Las infracciones continúan creciendo año tras año (38%, según PWC)
- Los robos de propiedad intelectual muestran un crecimiento significativo (56%, según PWC)
- El coste de las brechas de datos está creciendo continuamente.
- Nuevas regulaciones de privacidad (GDPR)
- Los consejos de administración están responsabilizando a CEOs y ejecutivos de las brechas de seguridad.
Con estas condiciones, las organizaciones deben tener un conocimiento completo de sus datos confidenciales y su riesgo para garantizar el cumplimiento de las políticas y leyes de privacidad, y las organizaciones deben supervisar cualquier actividad sospechosa, el acceso a datos no autorizados y remediar con controles de seguridad, alertas o notificaciones.
Se hace necesario el uso de algunas herramientas que ayuden a mitigar todo esto:
Productos de seguridad de datos
- Data Masking: Proporciona seguridad de datos y controles de privacidad para prevenir el acceso no autorizado y la divulgación de información sensible, privada y confidencial.
- Secure @ Source: Proporciona inteligencia de seguridad de datos para que las organizaciones puedan comprender los riesgos y vulnerabilidades de los datos confidenciales.
- Test Data Management: proporciona el aprovisionamiento seguro y automatizado de datasets que no son de producción para satisfacer necesidades de desarrollo.
- Data Archive: Podrás eliminar aplicaciones heredadas, administrar el crecimiento de los datos, mejorar el rendimiento de las aplicaciones y mantener el cumplimiento con el archivado estructurado.
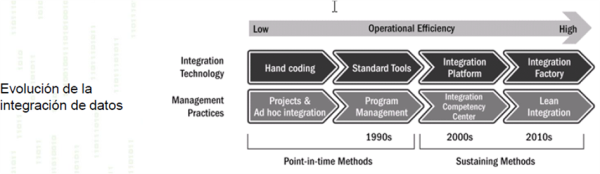
6. Data integration & interoperability - Gestión de la integridad de los datos: relacionado con el transporte y consolidación de los datos
La función Data integration & interoperability se refiere al conjunto de estándares y especificaciones necesarios para asegurar la integración de los datos en la organización.
Los departamentos de IT suelen trabajar con muchas aplicaciones que dan respuesta a los diferentes objetivos de negocio que se persiguen en las distintas áreas: una aplicación para CRM, otra para finanzas, bases de datos.
Problemas derivados de la falta de visión global
En una organización conviven muchas aplicaciones y muchos sistemas pero si no existe una cohesión se están perdiendo eficacia y visión, por tanto se está produciendo un menoscabo directo en la capacidad de decisión, que puede reflejarse en aspectos cotidianos tales como:
- La adquisición de nuevas herramientas: ya que al no tener definida una estrategia de interoperabilidad o integración de los datos, a la hora de analizar qué herramienta comprar no se tienen en cuenta las existentes y por tanto se desprecia el posible problema de comunicación que puede surgir entre ambas.
- La comunicación entre departamentos, para facturar o para evaluar resultados: en el primer caso las horas se imputarían en el Departamento de Proyectos, pero se facturarían en el de Contabilidad; mientras que en el segundo caso, por ejemplo, sería complicado analizar si una campaña de marketing promovida por el mismo Departamento ha sido efectiva o no ya que las ventas se contabilizan en el Departamento Comercial. Queda patente la necesidad de crear una interfaz que conecte los datos para evitar que queden almacenados como islas independientes y carentes de relación entre sí.
En qué consiste la función de Data Integration & Interoperability
En la función Data Integration & Interoperability intervienen dos conceptos:
- Interoperabilidad: se refiere a la habilidad de los diferentes sistemas de poder interactuar.
- Integración de los datos: se refiere al intercambio de datos entre los diferentes sistemas.
La integración es mucho más que el hecho de lograr que los sistemas se puedan comunicar. La integración implica entender cómo la información se guarda en los diferentes sistemas para que, al interactuar o interrelacionar, no sólo se conecte, sino que se entienda. Para ello es necesario crear políticas que garanticen tanto la interoperabilidad como la integración.
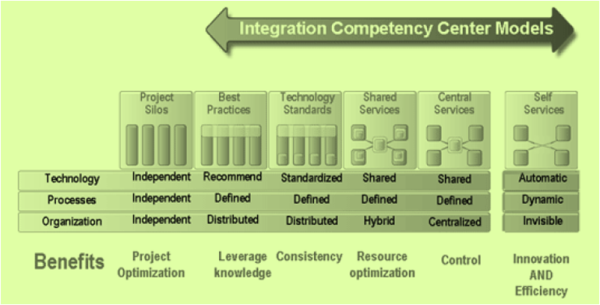
El Centro de Competencia de la Integración
La forma de gestionar eficazmente la integración es a través de la construcción de un Centro de Competencia de la Integración, que integra:
- Los silos que existen para cada proyecto.
- Las buenas prácticas.
- Los estándares tecnológicos.
- Los servicios compartidos.
- Los servicios centrales.
- Los servicios particulares de cada área.
A nivel de:
- Tecnología.
- Procesos.
- Organización.
El objetivo de esta función es resolver las inconsistencias de los canales de comunicación en las diferentes aplicaciones de la organización.
7. Documents & contents: establecimiento de las reglas que hay que aplicar a los datos fuera de las bases de datos.
Dentro de la gestión de datos, la función de Documents & Contents establece las reglas aplicables a los datos fuera de las bases de datos.
Con la estrategia correcta, cualquier organización puede cosechar beneficios centrándose en una gestión de documentos que incluya tres principios básicos:
- Personas.
- Procesos.
- Tecnología.
Para ello es necesario que intervengan en alguna de las siguientes funciones (relativas a documentos tanto electrónicos como físicos):
- Almacenar documentación.
- Inventariar documentos.
- Controlar información y documentación.
La gestión de contenidos en la organización
La gestión de contenidos es complementaria a la gestión de documentos. Incluye los recursos necesarios para:
- organizar
- categorizar
- y estructurar
... el acceso al contenido de dichos documentos.
En definitiva, esta función se refiere a toda la documentación que tiene la empresa y que no es relacional y a la gestión de dichos contenidos.
Cuando una organización se plantea la integración se refiere a un tipo de datos, los que se pueden relacionar, pero aparte de esa información también existe otro tipo de documentación (contratos, facturas, manuales, etc.) que no es relacional pero que, sin embargo, se debe igualmente gestionar. Para ello hay que crear la estructura necesaria que permita almacenarlos y organizarlos, ya que son información de la valiosa para la empresa y uno de sus activos.
El objetivo que persigue la función de Documents & Contents es que la organización utilice eficientemente el contenido.
Personas, procesos, tecnología y su relación con la calidad de datos
Para muchas personas, administrar la calidad de los datos puede ser una tarea desalentadora. Se trata de un problema importante con consecuencias financieras para su organización, pero no saben cómo proceder para gestionarlo. Sin embargo, con la estrategia correcta, cualquier organización puede cosechar beneficios en la calidad de datos, centrándose en tres principios básicos: Gente, Proceso y Tecnología.
Se trata de las piedras angulares de un enfoque estructurado de la calidad de los datos que se puede implementar y administrar. Y, lo que es más importante, un marco que permite rastrear el ROI de una calidad de datos exitosa.Personas
Lo más importante que una organización puede hacer por la calidad de los datos es dedicarle recursos específicos. Es mucho más fácil de ver cuando se observa el
coste del bad data: por ejemplo, una investigación muestra que el 25% de todos los registros de contacto contienen datos incorrectos, un tercio de los clientes potenciales utiliza nombres falsos y la mitad de todos los números de teléfono proporcionados no son reales. Añadiendo esto a los costes directos de adquisición de clientes, las oportunidades de ventas perdidas, los costes de atención al cliente e incluso las posibles multas de incumplimientos, se tiene la justificación financiera necesaria para disponer de gente para controlar la calidad de datos.
Procesos
Una de las funciones más importantes de un controlador de acceso de datos es contar con procesos para gestionar los puntos de contacto para sus datos, diseñar la calidad de los datos en el front end del cliente y la adquisición de leads, y el mantenimiento de estos datos en el transcurso de su ciclo de vida. Tener las políticas y los procedimientos adecuados te permite controlar los datos y puede hacer que la mecánica de la calidad de los datos sea sencilla y rentable.Tecnología
El uso de herramientas automatizadas para la calidad de datos es una estrategia sorprendentemente rentable y puede generar un gran retorno de la inversión. Las herramientas automatizadas pueden ser tan simples como verificar una dirección, o tan sofisticadas como crear una clasificación estadística para la calidad de un registro de prospecto o contacto. Utilizadas de manera adecuada, estas herramientas pueden poner gran parte del duro trabajo de la calidad de los datos en piloto automático para tu organización.
8. Reference & master data: gestión de datos compartidos para reducir la cantidad de información redundante, mejorar la calidad de los datos y obtener una visión global de la información.
En la gestión de datos, la función de Reference & Master Data se encarga de asegurar que los datos más importantes para el negocio son creados con la consistencia y calidad necesarias.
Reference Data son los conjuntos de datos o clasificaciones referenciados por los sistemas, aplicaciones, procesos e informes, así como por los sistemas transaccionales y registros maestros.
Estandarizar los datos de referencia, es decir, desarrollar esta función; es clave para la integración e interoperabilidad de los diferentes sistemas.
Los datos de referencia deben ser utilizados para la clasificación y análisis de la información, por ello es importante usar datos de referencia estándar, es decir, fijados por agencias reguladoras o gobiernos, cuando sea posible.
Ejemplo de este tipo de datos serían:
- Género.
- Código de país.
- Tipo de producto.
Los datos de que se ocupa esta función son necesarios para la empresa pero no son tan importantes para el negocio y su misión.
Los datos maestrosMaster data son las entidades de negocio que se involucran en todos los departamentos de la empresa, e incluso sus partners. Son los datos maestros.
Este tipo de datos son utilizados en múltiples procesos de la organización, por lo que es crítico estandarizarlos y sincronizar los diferentes sistemas donde se almacenan. El negocio necesita tener una visión 360º sobre estos datos para poder tomar decisiones alineadas con su visión.
Los datos maestros están relacionados con los datos de referencia y ejemplo de ellos serían los siguientes:
- Cliente.
- Empleado.
- Producto.
El mayor riesgo que se corre en una organización, si no se ha implementado correctamente esta función, es que, si los datos están en general muy dispersos en diferentes aplicaciones y distintos sistemas, estos datos maestros resultan ser los más dispersos de todos, por lo que resultará muy difícil para la empresa el tener una visión global de su propia organización.
Un ejemplo muy claro de la importancia estratégica de los datos maestros es el caso de una entidad financiera, en la que un empleado puede ser al mismo tiempo cliente, y tener sus cuentas bancarias y las de otros miembros de su familia contratadas con dicha entidad. Si no se ha estandarizado la información sobre esta persona aparecerá ligada al departamento de RR.HH, por su cualidad de empleado, y al Comercial, en calidad de cliente, pero se la entidad financiera se estará privando de una visión global que le permita tener identificado al individuo.
El objetivo que se logra a través de esta función es mejorar la gestión del negocio y ser más competitivo.
9. Data Warehousing & BI: gestión del proceso de datos analítico y acceso a datos que servirán de apoyo para la toma de decisiones.
La función de Data Warehousing & BI se ocupa de todo lo referente a datos históricos y analíticos dentro de la gestión de datos.
Data Warehousing es la combinación de dos elementos que soportan los requisitos históricos, analíticos y de BI y son los siguientes:
- El primero de ellos es una base de datos integrada que permite el análisis de la información.
- El segundo es la tecnología utilizada para recoger, limpiar, transformar, cargar y almacenar la información de diferentes orígenes.
Data Warehousing es el término utilizado para describir la extracción, limpieza, transformación y carga de los datos operacionales que alimentan el Data Warehouse.
La toma de decisiones en Data Warehousing y el BI
El Data Warehousing es la solución que permite hacer Business Intelligence (BI), que es un conjunto de capacitaciones de negocio que en ella se integran y que permiten analizar datos estratégicos para tomar decisiones que aseguren:
- Los objetivos estratégicos.
- La gestión de riesgos.
- Las normativas.
El Data Warehousing y el BI, dentro de un proyecto de Governance, suponen que, una vez implementado el marco, el proyecto marque las políticas que se han establecido de manera segura y cumpliendo con la legislación vigente, todo ello sin perder de vista los objetivos estratégicos fijados. El beneficio de esta función es poder analizar la información de que se dispone, lo que entre otras cosas, permite ahorrar costes.
Los objetivos de la implementación de BI son el adquirir una visión integrada que permita mejorar la toma de decisiones, mientras que el objetivo de Data Warehouse es permitir la implementación de BI.
10. Meta-data: indexación de la información que contiene una base de datos.
Con el asentamiento de las nuevas tecnologías y todo lo relacionado con el entorno virtual, el concepto de metadatos ha cobrado especial protagonismo. En el sector de la informática es muy utilizado y
siempre está relacionado con los datos que se utilizan para describir otro tipo de datos.
1. Definiciones de metadatos
Los metadatos son un término que se acuñó en los años 60 para describir un conjunto de datos, pero es ahora cuando está obteniendo más importancia y cuando más se está escuchando por el mundo virtual. Su primera acepción fue la de dato sobre dato, pero a partir de 2004 fue evolucionando hasta convertirse en los que hoy conocemos: metadatos.
La etimología de este término consta de dos palabras, una griega y otra latina. Por un lado la palabra griega “meta”, que significa después de o más allá de, y por otro lado el vocablo latino “datum”, que significa dato. Así mismo, se forma la expresión metadatos como más allá de los datos. En base a esto, metadatos son un conjunto de datos que describen el contenido informativo de un recurso, de archivos o de información de los mismos. Es decir, es información que describe otros datos. No obstante, la palabra metadatos no tiene una definición exclusiva, ya que son varias las expresiones con las que se conoce, tales como informaciones sobre datos, informaciones sobre informaciones o datos sobre informaciones.
A pesar de que la palabra metadatos se emplea en la actualidad, generalmente para el ámbito de la informática, el concepto es anterior a Internet, si bien el interés que ha suscitado ha hecho que se utilice en este entorno. El término metadatos es principalmente muy usado en el ámbito de la informática, enfocado a las empresas debido a la adquisición de una relevancia única en los últimos tiempos como consecuencia de las grandes cantidades de información que se manejan actualmente en las compañías. Por ello se emplean los metadatos como ayuda para gestionar los datos o información con que trabajan para una mayor efectividad y rendimiento.
2. ¿Cuáles son sus usos?
Aunque los metadatos tienen una utilidad concreta, es cierto que se pueden usar para muchas más cosas que la esencial. Debido a ello, los metadatos tienen como característica principal que son multifuncionales. Es una herramienta que tiene múltiples ventajas que posibilitan una buena administración de los datos cuando se llevan a cabo los procesos de gestión y gobierno de la información contenida. Así, vamos a detallar todas las funciones que tienen los metadatos:
- Facilitan la búsqueda y el análisis: los metadatos ayudan a buscar los datos más fácilmente y permiten realizar el análisis de los datos desde la propia fuente, favoreciendo la autodocumentación, la transformación y el reporting, entre otras funciones.
- Mejora la gobernanza de los datos: gestionar los metadatos en un entorno estandarizado hace posible la buena gobernanza de los datos y esto, a su vez, hace que el programa sea exitoso.
- Ayuda a la integración: empleando los metadatos para el uso conjunto entre usuarios de TI y de empresas, se permite que haya una mejor integración completa. De esta manera también ayuda a mejorar la gestión de los datos de manera más global.
- Facilita la estandarización: esto es posible gracias a la eliminación de errores y debilidades. Así, mejora la calidad de los metadatos en el transcurso de su ciclo de vida. Además, a través de la gestión de estos, se consigue tener una visión más completa de dicho ciclo, de principio a fin.
- Mejora los informes: la correcta gestión de los metadatos hará que los informes sean mejores, permitiendo entregarlos de manera segura y fiable. Esto se debe a la facilidad de intervención que hace que los procesos sean de mayor calidad.
- Realiza desarrollos más rápidos: acceder a los metadatos de manera inteligente incrementa la producción de los creadores y minimiza el período de abastecimiento de la conectividad. Esto hace que se rebajen los costes de las modificaciones que se produzcan.
- Gestiona los cambios: gracias a la gestión de los metadatos se ofrece una visión mejorada, así como el control que se requiere para la integración de los datos empresariales. Los cambios se observarán por medio de la automatización de los estudios de impacto, por lo que se podrá actuar para resolver los problemas que puedan surgir debido a ello.
- Mayor seguridad: en el supuesto de que se produzcan cambios, se deberán proteger los datos críticos de la empresa, así como ayudar a que se cumpla estrictamente la normativa en cuestión. Esto puede hacerse como consecuencia de la apropiada gestión de los metadatos.
3. Clasificación de metadatos
En base a todo lo relacionado anteriormente, se puede ver que los metadatos son una herramienta que proporciona la ayuda necesaria a las empresas que dominan una gran cantidad de información, organizándola para facilitar el trabajo de los usuarios y acelerando su productividad. Además, son muchos los usos para los que se emplean los metadatos, pero antes de seguir avanzando en materia debemos hacer un alto en el camino, para conocer la clasificación de los metadatos en cuanto a sus funciones. Así, estos se clasifican usando tres criterios esenciales, diferenciados por: su función, su variabilidad y su contenido.
- Por su función: en esta primera clasificación, se entiende que los datos que se manejen pueden pertenecer a uno de los tres tipos de funciones que tiene: lógicos, simbólicos o subsimbólicos. Detallándolos brevemente, podemos decir que los lógicos son datos que explican de qué manera los datos simbólicos pueden usarse para hacer deducciones de resultados lógicos, por lo que se caracterizan por la compresión. Los datos simbólicos son aquellos que detallan los datos subsimbólicos, por lo que agregan sentido. Y por último, los datos subsimbólicos son lo que no contienen información alguna sobre su significado.
- Por su variabilidad: en este aspecto, los metadatos se pueden clasificar según la variabilidad de los mismos, en dos grupos. Por un lado, estarían los inmutables, que son los datos que no cambian independientemente de la parte del recurso que sea visible. Y, por otro lado, estarían los mutables, que son aquellos que son diferentes de los demás e incluso difieren de parte a parte.
- Por su contenido: esta última clasificación es la más usual. En este caso, se fraccionan los metadatos por su contenido. De este modo, se da la posibilidad de distinguir entre los metadatos que detallan el recurso en sí y los metadatos que describen el contenido de ese recurso. Sin embargo, se puede incluso subdividir estos dos grupos en más subgrupos dependiendo de la precisión con la que queramos llevar la clasificación de los datos.
4. El ciclo de la vida de los metadatos
Los metadatos tienen una estructura en cuanto a las funciones que realizan. Es decir, tienen un ciclo de vida que va detallando cada etapa por la que pasa, haciendo determinadas labores en cada una de ellas. Así, en este aspecto podemos diferenciar el ciclo de vida de los metadatos en tres fases: creación, manipulación y destrucción.
- Creación: en esta etapa es cuando se crean los metadatos. Estos pueden desarrollarse de diferentes maneras, ya sea manualmente, automáticamente o semiautomáticamente.
- Forma manual: puede llegar a ser un procedimiento un tanto complicado, aunque todo depende del formato que se utilice y del volumen que se esté buscando. De todos modos, es más usada cualquiera de las otras dos formas de creación que detallamos a continuación.
- Forma automática: en este caso, el software recibe toda la información requerida por sí solo, es decir, sin ningún tipo de ayuda externa. Sin embargo, a pesar de los avances tecnológicos en cuanto a los algoritmos que se emplean en este aspecto, es poco viable que el ordenador consiga por sí mismo, sacar todos y cada uno de los metadatos de manera automática. Así que esta forma tampoco llega a ser la más adecuada, aunque también se use de forma frecuente.
- Forma semiautomática: esta es la manera ideal para crear metadatos. Mediante este sistema se establecen una serie de algoritmos autónomos que sostiene el usuario en cuestión y que no permiten que el software pueda sacar por sí mismo los datos deseados, sino que necesita ayuda externa para ello.
- Manipulación: en esta fase se llevan a cabo cambios en determinados aspectos. Por ello, si los datos en cuestión cambian, los metadatos también deben cambiar y esto se realizará fácilmente y de manera automática, aunque hay ocasiones en las que se necesita ayuda humana para urdir esta labor.
- Destrucción: como última fase que puede realizarse en la vida de los metadatos está la destrucción de los mismos. En este caso hay que estudiar bien la manera de hacerlo. En determinadas ocasiones se eliminan los metadatos a la misma vez que sus recursos de manera conjunta. Sin embargo, hay otras situaciones en las que se conservan los metadatos por diferentes motivos, como por ejemplo para controlar las modificaciones en un documento.
5. ¿Cuál es el uso común de los metadatos?
Como ya hemos podido comprobar en un apartado anterior, el término metadatos tiene varios usos. Sin embargo,
hay un uso común que es el más frecuente y es la refinación de consultas a buscadores. De esta manera, se ayuda al usuario a encontrar unos resultados más precisos y a no perder tiempo buscando de manera manual. Así mismo,
los metadatos proporcionan la asistencia necesaria para categorizar las informaciones que están disponibles y hacer más sencilla la comunicación entre el usuario y el ordenador. Por tanto, los metadatos facilitan el trabajo clasificando y estructurando los datos disponibles.
6. Almacenamiento de los metadatos
Ya hemos tanteado la cuestión de cómo se clasifican los metadatos según los datos o informaciones que contienen, pero aún quedan otros interrogantes como el caso de dónde se pueden almacenar los metadatos para tenerlos a buen recaudo y bien organizados. En este caso, existen dos maneras de guardar los metadatos de manera segura:
- Depósito interno: es decir, depositar los metadatos internamente en el mismo archivo que los datos.
- Depósito externo: se trata de depositarlos externamente en su mismo recurso.
En principio, los metadatos se solían almacenar de manera interna en el mismo documento o archivo que los propios datos y esto se hacía con el objetivo de permitir una administración favorable de los mismos. En cambio, hoy en día se suele considerar como la mejor elección de almacenamiento el depósito externo. Esto es debido a que de esta manera se da la posibilidad de que los metadatos se agrupen para mejorar las acciones de búsqueda. No obstante, hay un problema en este aspecto. Se trata de la forma de unir un recurso con sus metadatos. En este sentido, en la mayoría de los casos se utiliza la técnica URIs, que localiza los documentos en la World Wide Web, aunque esto también genera otro problema a su vez y es que no todos disponen de documentos que tengan URL. Así que es un tema algo complicado y que debe estudiarse a fondo para tomar las decisiones de la mejor manera posible.
Sin embargo, hay un aspecto que hay que destacar respecto al almacenamiento de metadatos: la codificación. En base a esto originariamente se guardaban los metadatos empleando textos no cifrados o incluso la codificación binaria para almacenarlos en ficheros determinados. Pero en la actualidad es habitual utilizar para realizar esta labor el Extensible Markup Language (XML), que ayuda a definir los lenguajes de marcas creadas por el World Wide Web Consortium usado para almacenar datos de forma legible. Esto se aplica tanto para los usuarios como para los propios ordenadores, ya que es un lenguaje que dispone de muchas características que lo hacen ser el adecuado para estos casos. Aunque a pesar de las ventajas que conlleva también dispone de una serie de inconvenientes, como el espacio de la memoria, ya que los datos requieren de más volumen del que proporciona el formato binario. No obstante, debido a esto hay muchos supuestos en los que se unen ambos recursos (XML y codificación binaria) para unificar las ventajas de los dos sistemas y que se genere en una mejor labor de almacenamiento.
11. Data quality: definición, control y mejora de la calidad de los datos de acuerdo con las necesidades del proyecto.
Calidad de datos es la cualidad de un conjunto de información recogida en una base de datos, un sistema de información o un data warehouse que reúne entre sus atributos la exactitud, completitud, integridad, actualización, coherencia, relevancia, accesibilidad y confiabilidad necesarias para resultar útiles al procesamiento, análisis y cualquier otro fin que un usuario quiera darles.¿Big Data? Sin duda hacer uso de él es una posibilidad para poder tomar buenas decisiones de negocio. Pero sin calidad de datos sólo vas a conseguir decisiones pobres. Ahora más que nunca, es de vital importancia asegurar la calidad de datos para apoyar las acciones empresariales. ¿De qué sirve realizar análisis y llegar a conclusiones para apoyar la toma de decisiones si la calidad de datos es deficiente? Una mala calidad de datos puede provocar decisiones erróneas que te pueden llevar a tener dificultades.
Veamos exactamente qué es calidad de datos y algunas otras cosas que debes tener en cuenta acerca de esta disciplina.
1. Definición de calidad de datos
La calidad de los datos es más que una percepción. No existen estandarizaciones, ni una talla única en lo que se refiere a data quality. Mantener la exactitud y la integridad de todos los tipos de datos en toda la organización es trabajar por su aptitud para cumplir con su propósito en un contexto dado, implica garantizar que cada dato reúne todos los atributos necesarios:
Dentro de una organización, la calidad de los datos es esencial para la consistencia del reporting, la confianza de los usuarios y para la eficacia de los procesos operativos y transaccionales. La inteligencia empresarial necesita basarse en datos de alta calidad y, para asegurar que éstos se hallan al nivel deseado, hay que cuidar que cada interacción con los datos lo propicia, desde la forma en que se introducen, a cómo se almacenan y gestionan.
El aseguramiento de la calidad de los datos es el proceso de verificación de la fiabilidad y efectividad de los datos, que debe realizarse periódicamente, y que incluye acciones como:
- Actualización
- Normalización
- De-duplicación
Toda organización debe buscar el obtener una visión única de la verdad, independientemente de que para alcanzar su conocimiento necesite apoyarse en datos de distintos tipos, que éstos se almacenen en múltiples sistemas dispares o provengan de fuentes heterogéneas.
Para garantizar la calidad de datos existen muchas soluciones en el mercado que facilitan los procesos de limpieza, perfilado y data matching, contribuyendo a lograr mejores resultados, en menos tiempo, gracias a la automatización que, al mismo tiempo, reduce el índice de errores en el proceso.
2. ¿Qué es Data Quality Management?
La gestión de la calidad de los datos (Data Quality Management) es una forma de administración que abarca desde la definición y designación de roles hasta el despliegue de funciones, de la definición de políticas y responsabilidades al establecimiento de procedimientos para la adquisición, mantenimiento, disposición y distribución de datos.
Un enfoque eficaz de la gestión de la calidad de los datos comprende tanto elementos reactivos, que incluyen la gestión de problemas en los datos situados en bases de datos existentes; como elementos proactivos, que son los que tiene que ver con:
- Establecimiento de la gobernanza.
- Identificación de las funciones y responsabilidades.
- Creación de las expectativas de calidad, así como de las estrategias empresariales de apoyo.
- Implementación de una plataforma técnica que facilite estas prácticas empresariales.
Por eso, para que una iniciativa de gestión de la calidad de los datos tenga éxito, debe garantizarse la cooperación entre las áreas de IT y negocio. Esta asociación es importante porque, si bien los perfiles técnicos se encargarán de la construcción y el control del entorno, los usuarios de negocio serán los propietarios de los datos y, a partir de la aceptación ese rol, asumirán una responsabilidad con la organización y sus activos informacionales.
Así, desde IT se llevarán a cabo todas las acciones necesarias para adquirir, mantener, difundir y poner a disposición de quien corresponda los activos de datos electrónicos de una organización, trabajando para ello en:
- Arquitectura
- Sistemas
- Establecimientos técnicos
- Bases de datos
En cualquier proyecto de data quality, o al considerar una plataforma de inteligencia de negocios, hay que tener en cuenta los diferentes roles asociados con la gestión de la calidad de los datos:
- Responsable de proyecto y gerente de programa: es la persona que se encargará de la supervisión de las iniciativas de calidad específicas o del programa de inteligencia de negocios. Entre sus funciones, está también el gestionar el presupuesto, el alcance y las limitaciones del proyecto.
- Agente de cambio en la organización: se trata de una posición clave puesto que su misión consiste en ayudar a todos los integrantes de la compañía a reconocer el impacto y el valor del entorno de inteligencia de negocios, prestando su colaboración para hacer frente a los posibles retos que se planteen.
- Analista de negocio: con este rol se designa al perfil encargado de comunicar las necesidades del negocio para traducirlas en necesidades de calidad de datos.
- Analista de datos: una vez conocidas las demandas del área de negocio, traduce esas necesidades en el modelo de datos y los prerrequisitos para los procedimientos de adquisición y entrega de datos; teniendo siempre presentes las necesidades específicas de calidad, y asegurándose de que queda constancia de ellas en el diseño.
- Administrador de datos: así se denomina a quien se ocupa de gestionar los datos como un activo corporativo.
3. Hasta dónde llegar con la calidad de datos
¿Existe alguna forma de medir el data quality? ¿Es posible llegar a una tasa de errores igual a cero? ¿Cómo se puede optimizar la inversión en este área? Lo cierto es que, aunque todo el mundo oye hablar de la calidad de datos, mucha gente no tiene del todo claro a qué se refiere el término o hasta dónde se puede o debe llegar con este tipo de cuestiones.
El primer paso para alejar la confusión y poder centrarse en lo verdaderamente importante es olvidarse de mitos. Y, precisamente,
una de las leyendas más extendidas en este campo es la que tiene que ver con lograr activos informacionales 100% libres de errores.
Proponerse este objetivo es crear un pozo de inversión sin fondo y sin fundamento ya que, si en entornos tradicionales podría quizás plantearse, con los sitios web y el big data resulta casi imposible. El fin en ningún caso justifica los medios, puesto que los datos sólo necesitan ajustarse a los
estándares que se han establecido para ello.
Y, ¿Cuáles son estos estándares? Para poder responder a esta pregunta, primero habría que determinar qué es la calidad y eso es posible cuando se conoce:
- Quién crea los requisitos.
- Cuál es el proceso por el que se definen.
- Hasta dónde llegan los márgenes entre los que moverse para que el cumplimiento de requisitos se pueda considerar aceptable.
La respuesta a estas cuestiones suele tenerla el administrador de datos, que es quien establece los requisitos y entiende las necesidades que los motivan. Quien ostenta este rol es, además, la persona que determina el nivel de tolerancia a errores, que no suele ser cero. El motivo es que todo, desde la recolección de los datos hasta su adaptación a las necesidades de la empresa, es una vía de aparición a posibles errores. Tener datos que son 100% completos y 100% precisos no sólo es increíblemente caro, sino que además lleva mucho tiempo de conseguir y no influye apenas en el ROI.
4. Cómo podemos medir la calidad de datos
Llevar a cabo una gestión de la calidad de datos adecuada depende de saber cómo medirla. El establecimiento de indicadores y la recogida de métricas permiten ganar en comprensión acerca de cada componente del ciclo de calidad de datos porque, aunque cada organización es única, existen una serie de medidas cuantitativas del data quality que son universales:
- Completitud: es el grado en el que todos los atributos del dato están presentes.
- Validez: representa el ajuste de un valor de datos a su conjunto de valores de.
- Unicidad: la medida en que todos los valores distintos de un elemento de datos aparecen sólo una vez.
- Integridad: tiene que ver con el grado de conformidad con las reglas de relación de datos definidas.
- Precisión: determina en qué medida los datos representan correctamente la verdad sobre un objeto del mundo real o se ajustan a lo establecido por una fuente autorizada.
- Coherencia: representa el grado en que una pieza única de datos contiene el mismo valor a través de múltiples conjuntos de datos.
- Oportunidad: este atributo de la calidad de datos permite conocer si éstos están disponibles cuando se requiere.
- Representación: tiene que ver con el formato, patrón, legibilidad y utilidad de los datos para su uso previsto.
Además de estas medidas cuantitativas de calidad de datos, para adquirir una perspectiva real de la situación de la organización en este área, también deben considerarse las medidas cualitativas, como las que tienen que ver con la satisfacción de los clientes y usuarios de negocio, los índices de cumplimiento, la aparición de redundancias en los procesos o la identificación de oportunidades de negocio.
El establecimiento de indicadores permite establecer una línea base para conocer el estado de la calidad de datos en la organización y poder monitorizar el progreso de las iniciativas de gestión de data quality.
.5. Que hace falta para gestionar la calidad de los datos
Además de las métricas existen algunos otros componentes fundamentales del ciclo de calidad de datos. Se trata de los siguientes:
- Descubrimiento de datos: proceso de búsqueda, recopilación, organización y notificación de metadatos.
- Perfilado de datos: proceso de analizar los datos en detalle, comparándolos con sus metadatos, calculando estadísticas de datos e informando de las medidas de calidad de los datos que se deben aplicar en cada momento.
- Reglas de calidad de datos: se orientarán a optimizar el nivel de calidad de los activos informacionales de la organización y, para ello, se basarán en los requisitos de negocio aplicables, las reglas comerciales y técnicas a las que deben adherirse los datos.
- Monitorización de la calidad de los datos: la mejora continua requiere de un esfuerzo de seguimiento, que permita comparar los logros con los umbrales de error definidos, la creación y almacenamiento de excepciones de calidad de datos y la generación de notificaciones asociadas.
- Reporting de calidad de datos: está relacionado con los procedimientos y herramientas empleadas para informar, detallar excepciones y actualizar las medidas de calidad de datos en curso.
- Corrección de datos: se ocupa de la corrección en curso de las excepciones y problemas de calidad de datos según son notificadas.
Una vez que se cuenta con las métricas y están en marcha el resto de componentes, para establecer un programa de gestión de data quality sólo queda considerar algunos principios clave, como:
- Recordar que no se trata de una acción puntual. La calidad de datos he de entenderse como un proceso continuo donde no existe, ni debe plantearse un fin, sino un mayor ajuste. Este visión implica un cambio cultural en la organización que puede ser lo que más tiempo requiera en la iniciativa de calidad de datos. Asimismo, para garantizar su idoneidad, el programa de gestión debe ser reevaluado periódicamente y modificado según sea necesario.
- No tratar de abarcar todos los problemas de calidad de golpe ni intentar llegar a una cota cero de errores. Es inviable. En vez de intentar implementarlo todo a la vez, es preferible construir un programa que vaya resolviendo cuestiones de forma progresiva y paso a paso.
- Plantearse metas. Poner objetivos a corto, medio y largo plazo es una forma de motivarse hacia el progreso y la mejor manera de comprobar si se avanza en la dirección adecuada. En la práctica, una vez se entienden los niveles de calidad de datos requeridos por el negocio, pueden plantearse las metas de calidad de datos y establecer los primeros. Una buena política es priorizar las áreas que proporcionarán el retorno de inversión más alto y, a medida que se implementa la estrategia, empezar a centrar la atención en las cuestiones de mayor valor para el negocio.
- Estar abiertos a todo. Los datos son de todo tipo y provienen de múltiples fuentes. No hay que ponerse límites ni centrarse en un área en concreto, olvidando a las demás. La calidad de los datos se puede gestionar en cualquier punto del flujo de datos.
- No olvidar la importancia de los propietarios de los datos. Por muy bien diseñado que esté un programa de gestión de la calidad de datos, si los usuarios de negocio no conocen sus responsabilidades o las pasan por alto en sus interacciones con los activos informacionales de la organización, no se podrá avanzar hacia los objetivos de calidad. Igual que con los administradores del programa, una buena alternativa es considerar la vinculación de su compensación a los objetivos de calidad para aumentar su motivación y mejorar resultados.
6. Los pilares del Data Quality Management
Una vez entendida la importancia de la calidad de los datos es importante conocer los 5 pilares esenciales de la gestión de la calidad de los datos. Se trata de los siguientes:
Las personas y el talento
La tecnología es solo tan eficiente como las personas que la implementan. Podemos funcionar dentro de una sociedad comercial tecnológicamente avanzada, pero la supervisión humana y la implementación de procesos aún no se han vuelto obsoletas. Hay varias funciones de gestión de la calidad de los datos que deben tenerse en cuenta:
- Administrador del programa DQM: El rol del administrador del programa debe ser ocupado por un líder de alto nivel que acepte la responsabilidad de la supervisión general de las iniciativas de inteligencia empresarial. También debe supervisar la gestión de las actividades diarias que involucran el alcance de los datos, el presupuesto del proyecto y la implementación del programa. El gerente del programa debe liderar la visión de datos de calidad y retorno de la inversión.
- Administrador de cambios de organización: el administrador de cambios hace exactamente lo que sugiere el título: organizar. Asiste a la organización brindando claridad y conocimiento de soluciones avanzadas de tecnología de datos. Como los problemas de calidad a menudo se destacan con el uso de un software de tablero , el administrador de cambios juega un papel importante en la visualización de la calidad de los datos.
- Analista de negocios / datos: el analista de negocios define las necesidades de calidad de datos desde una perspectiva organizacional. Estas necesidades se cuantifican en modelos de datos para adquisición y entrega. Asegura que la teoría detrás de la calidad de los datos se comunica al equipo de desarrollo.
Perfilado de datos
La creación de perfiles de datos es un proceso esencial en el ciclo de vida de gestión de calidad de datos, tanto en el cloud, como en cualquier otro entorno. Data profiling se lleva a cabo con el propósito de desarrollar una visión más completa sobre los datos existentes, para poder compararlos con los objetivos de calidad de datos. Esto implica:
- Revisar la información al detalle.
- Comparar y contrastar los datos con sus propios metadatos.
- Ejecutar modelos estadísticos.
- Informar acerca de la calidad de los datos.
El perfilado de datos ayuda a las empresas a fijar, en base a métricas, un punto de partida en el proceso de gestión de la calidad de la información, estableciendo los estándares que permitirán elevar los niveles de data quality.
Definición de reglas de calidad de datos
El tercer pilar de la gestión de calidad de datos es la calidad en sí misma. El desarrollo de reglas de calidad es esencial para el éxito de cualquier proceso de data quality management, ya que estas normas facilitan la detección temprana de pérdidas de alineación, evitando que los datos comprometidos puedan afectar a todo el conjunto.
Las reglas de calidad que se aplicarán a la información, su uso y gestión, deben crearse y definirse en función de los objetivos y requisitos del negocio. Ha de tenerse en cuenta que los elementos de datos críticos deberían depender de la industria.
Las reglas de calidad de datos, tanto por sí mismas, como cuando se combinan con un software de Business Intelligence permiten a la organización:
- Identificar problemas de calidad de datos en los activos informacionales del negocio.
- Corregir estas cuestiones.
- Predecir tendencias.
- Contribuir con su aportación a ampliar el alcance del análisis.
- Elevar el valor del reporting.
Reporting
Dentro de un proceso natural de aplicación de reglas de datos no puede faltar la generación de informes de calidad. A través del reporting quedan registradas todas las excepciones comprometedoras de calidad de los datos puesto que, una vez que las excepciones han sido identificadas y capturadas, deben agregarse para poder identificar patrones de calidad de datos.
Los puntos de datos capturados se deben modelar y definir en función de características específicas (por ejemplo, en función de su fuente o fecha). Una vez que se han registrado estos datos, se pueden aplicar a una solución de inteligencia empresarial para informar sobre el estado de la calidad de los datos y las excepciones que existen. Lo ideal es que este proceso se produzca en tiempo real.
La rentabilidad de cualquier acción en materia de calidad de datos aumenta gracias a la monitorización y el reporting, ya que ambos permiten que las empresas identifiquen la ubicación y características de las excepciones de datos, brindando la visibilidad necesaria sobre el estado de los datos, en cualquier punto y en tiempo real. Contar con este respaldo permite a la empresa no demorar el diseño de estrategias para los procesos de remediación.
Reparación de datos
El aspecto más importante de la corrección de datos es la realización de un examen enfocado a hallar la causa de raíz de los problemas, para determinar por qué, dónde y cómo se originó el defecto de los datos.
Una vez que se haya implementado esta evaluación, el plan de reparación debería comenzar. La reparación de datos es un proceso que se estructura en torno a dos pasos, a través de los cuales se determina:
- La mejor manera de solucionar los defectos encontrados en los datos.
- El modo más eficiente de implementar el cambio.
Es probable que sea necesario reiniciar los procesos de datos que dependían de los datos previamente defectuosos, especialmente si su funcionamiento estaba en riesgo o comprometido por los datos defectuosos. También llegados a este punto, puede convenir hacer una nueva revisión de las reglas de calidad de datos, para determinar si deben ajustarse o actualizarse.
Una vez que se considera que los datos son de alta calidad, tanto en el cloud como on premise, se experimentará una mejoría en la ejecución de los procesos y funciones comerciales críticos, que también ganarán en precisión. Como resultado, la organización verá reducidos sus costes e impulsado su ROI.
7. Diferentes tipos de datos que afectan a la calidad de datos
Obtener datos limpios es un desafío porque requiere compartir información con precisión entre dispositivos y formatos que no se integran fácilmente. Hoy día es frecuente encontrar datos que no están limpios o datos desestructurados. Un problema añadido a las cuestiones de calidad de datos es que la mayoría de los sistemas requieren el uso de la entrada manual de datos, que expone a la organización a errores humanos.
Entre los tipos de datos que mayores efectos adversos pueden provocar en términos de calidad se encuentran los tres siguientes:
- Datos oscuros: son los datos que se recopilan, procesan y almacenan como parte de las actividades comerciales cotidianas, pero que no la organización no utiliza con ningún otro fin. Su existencia revela que el sistema de calidad de datos de la empresa no es el óptimo ni está lo suficientemente avanzado, puesto que permite que a la recopilación y gestión de datos les falte eficiencia y eficacia.
- Datos sucios: si on premise este tipo de datos supone un grave problema de calidad, en un entorno como la nube aún más, en especial en lo que respecta al IoT. En el ámbito de sistemas automatizados, los datos sucios pueden causar a la organización un daño real, al obligarla a incurrir en un costo económico real causado por las acciones automáticas que dan inicio con datos que no son válidos.
- Datos no estructurados: en ocasiones, los datos están disponibles, pero no están preparados para su uso. Deben ser enriquecidos de alguna manera para poder considerarse compatibles con el sistema que los va a consumir. Si no se hace, los problemas de calidad empezarán a aparecer.
8. Problemas y desafíos de la calidad de datos con Big Data
Para comprender los problemas de calidad de datos en Big Data, antes hay que entender las principales características que configuran a los grandes datos, ya que, aunque las cuestiones de data quality siempre han existido, la explosión Big Data y la aparición de nuevos entornos, como el cloud, han agregado una nueva dimensión al problema, que puede multiplicar el efecto negativo de sus consecuencias.
Existen 5 aspectos a tener en cuenta en lo que respecta a la gestión de la calidad de datos y Big Data:
- Velocidad: la velocidad a la que se generan los datos puede dificultar la medición de la calidad de los datos, dada la cantidad de tiempo necesario para aplicar los procesos y las limitaciones en los recursos. Para el momento de finalizar una evaluación de calidad, sus conclusiones podrían haber quedado ya obsoletas.
- Variedad: los datos procedentes de Big Data adoptan todo tipo de formatos y tiene una variedad de tamaños y esto afecta la calidad de los datos. Una métrica de datos puede no ser adecuada para todos los datos recopilados, lo que hace que sea preciso trabajar con métricas múltiples, ya que evaluar y mejorar la calidad de los datos no estructurados es mucho más complejo que conseguirlo con los datos estructurados. Para dar sentido a estos datos que llegan de fuentes diversas, se necesitan metadatos confiables, que pueden ser difíciles de obtener cuando la procedencia es externa.
- Volumen: el tamaño y escala masivos de los proyectos de Big Data hace que sea casi imposible llevar a cabo una evaluación de calidad de datos de gran alcance. La falta de precisión es uno de los problemas más habituales, al que habría que añadir la complejidad que supone el tener que redefinir las métricas de la calidad de datos en función de los atributos particulares de cada proyecto Big Data.
- Valor: el valor de los datos es todo lo útil que es en su propósito final y esto nos lleva a plantearnos que, en algunos casos, la calidad puede ser suficiente y no interesar el esfuerzo que implica introducir mejoras. Esta decisión se verá influida por la relación coste - beneficio de mejorar la calidad de los datos y el establecimiento de prioridades de la organización.
- Veracidad: la veracidad está directamente relacionada con los problemas de calidad en los datos. Se relaciona con la imprecisión de los datos, que, a su vez, tiene que ver con sus sesgos, consistencia, confiabilidad y ruido. Todos ellos afectan a la integridad de los datos pero, dado que existen distintas ideas acerca de lo que constituye data quality, en cada empresa y, dentro de ella, en sus diferentes componentes, los usuarios de datos tendrán distintos objetivos y procesos de trabajo.
9. La calidad de datos en el mundo del IoT
Según un documento técnico reciente de Cisco, el 82% de dispositivos conectados será inteligentes para el año 2021. El cambio a dispositivos inteligentes y conectados hará que, para 2025, el consumidor promedio tenga más de 4.700 interacciones por día con las organizaciones a las que está conectado. El resultado es una mayor facilidad de recopilación de datos sobre los consumidores, que provocará el rápido crecimiento del almacenamiento de datos en la empresa.
Esto es motivo de preocupación para los CEO, que, tal y como revelan datos de KPMG, en el 84% de los casos se muestran preocupados por la calidad de los datos en los que basan sus decisiones. No es para menos, actualmente,
se estima que hasta el 30% de los datos en las empresas son de baja calidad. De hecho,
una parte significativa de los datos empresariales se degrada en menos de 3 meses desde el momento inicial de recopilación.
Estar preparado para recopilar datos de 28 mil millones de dispositivos conectados representa un gran desafío para las organizaciones que han desarrollado su infraestructura para limpiar, almacenar y analizar el tráfico en función de los aportes humanos tradicionales.
Pero no es el único reto, ya que, aunque con los datos tradicionales, nos hemos acostumbrado a la idea de que las personas son las principales fuentes de problemas de calidad de datos, también
puede empezar a suceder que sean los propios dispositivos los que introduzcan errores significativos en la calidad de los datos.
Internet of Things ofrece un tremendo potencial a las organizaciones, pero
establecer estándares y garantizar que los datos se normalicen entre sistemas es clave para garantizar que los datos recopilados de los dispositivos IoT se conviertan en datos valiosos.
Por el momento, sólo una de cada tres empresas tiene datos integrados en procesos y sistemas en tiempo real, lo que presenta un desafío significativo para quienes buscan aprovechar la ola de datos impulsados por IoT.
¿Cómo gestionará tu negocio el rápido aumento en la recopilación de datos y los posibles problemas de calidad de datos que surgirán con la adopción generalizada de IoT? ¿Cómo hará frente a las cuestiones de data quality que vayan apareciendo a medida que llegan nuevos avances tecnológicos en entornos como el cloud?
Referencias
- https://www.cognodata.com/blog/arquitectura-datos-estrategia-diferenciadora/
- https://www.powerdata.es/



.jpeg)